3. 数据清洗
数据清洗是针对数据中存在的重复、缺失、格式不一致等问题的处理过程。它包括缺失值处理、异常值识别与处理、数据归一化等步骤。
缺失值处理通常有两种方法 一是通过插值、估算等技术生成符合统计规律的估算值来替代缺失值;二是直接删除包含缺失数据的记录。异常值处理则是通过统计分析来识别并处理异常记录,例如年龄明显超出合理范围、身高体重明显异常的记录,这些记录可以通过置空或人工审核修订的方式来处理。数据归一化则是针对同一字段的不同表示方式进行统一,例如将性别字段中的“男/女”、“F/M”等不同编码统一,或将所有时间记录统一为“年-月-日”的格式,将所有空值记录统一表示为null等。
此外,还需要对编码方式进行统一,例如罗马数字、中文、阿拉伯数字混用,全角字符和半角字符混用等情况。同时,还需对脏数据进行处理,如错误地将身高记录为姓名,字符后的多余空格、乱码或不可见字符等。通过这些清洗步骤,可以提高数据的质量和一致性,为后续的数据分析和研究打下坚实的基础。
4. 数据结构化
对于出院小结、病理结果等长文本数据,需进行结构化提取,从文本中整理并提取关键信息。如从以下病理活检结论:“<食管>低~中分化鳞状细胞癌,侵及外膜。两断端均未见癌累及。<淋巴结>“7组”淋巴结3枚及“17组”淋巴结4枚均未见癌转移。”中提取分化程度,肿瘤类型,淋巴结转移情况,侵及部位等字段信息,就属于典型的文本结构化。
结构化方法包括人工处理、正则匹配、基于自然语言处理(NLP)的技术等:
人工处理数据的方式能够达到很高的精度,但这一过程往往耗时较长。在处理半结构化数据时,可以采用正则匹配的方式来提取信息,正则匹配是通过运用特定的正则表达式,精确地匹配并提取需要的字段和内容。近年来NLP技术在文本结构化方面得到大规模应用,虽然NLP在处理大规模文本数据时表现出色,
但其识别准确率还有待进一步提升。为了提高识别准确率,高质量的数据标注、算力提升、算法优化都是必不可少的,但这些可能会额外增加成本。
为了更有效地处理海量文本数据,可以结合上述方式,在效率和质量上达成平衡。此外,大型语言模型如GPT、LLaMA等在文本生成、人机对话、文本理解等方面展现了巨大的应用潜力。利用大模型API完成长文本结构化成为了未来的发展方向。通过这些先进的技术,可以更高效地处理临床研究中的长文本数据,为医学研究和决策提供有力的支持。
5. 数据标注
随着科研的不断深入,新的数据处理需求也不断产生。以近年来蓬勃发展的影像组学为例,为了更精确地分析DICOM等格式的影像数据,还需要对某些图像区域进行标注处理。如图13-3,要实现CT影像中器官或肿瘤部位的自动化识别,需要人工标注大量训练样本,来开展基于监督学习算法的预测。
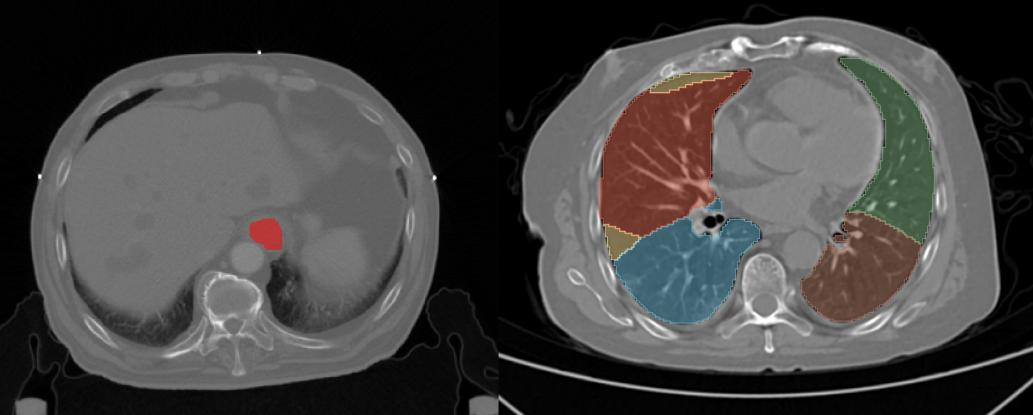
图13-3 医学影像的分割示例(左:食管癌人工标化感兴趣区域,右:深度学习肺部影像数据分割)
在进行影像数据标注时,标注人员必须具备相应的影像学知识储备,才能够在各类图像中,准确地判断出病灶的具体位置和范围,并进行勾画,这是确保数据标注准确性和研究质量的关键,培训以及抽样检查是必不可少的步骤。